

如果摄像头是汽车的眼睛,那它的世界是什么样的?

我们在成长到两三岁的时候都要做的一件事就是学走路。我们用眼睛看、用手去摸、用所有的感知器官去接触周围的环境。可汽车并不像人类一样拥有这些与生俱来的感知方式,那汽车是通过怎样的方式完成对周围环境的感知从而实现自动驾驶的呢?
也许你会说,通过对摄像头、毫米波雷达、激光雷达的综合使用,不就完成了对车子 360 度全范围的观测了吗?然后检测到哪里有障碍物就在哪里停下来,多简单啊。
道理虽然简单,但其实具体的实现还是很复杂的。比如:车子通过摄像头捕捉到了一个图像,它怎么分辨出哪里是路,哪里是墙?
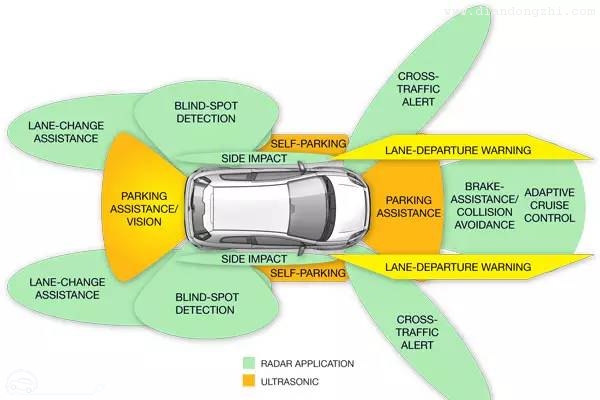
就像我们日常开车一样,自动驾驶也需要感知到人类开车时需要的那些信息,比如车道线的位置、与前车的距离等等,车辆是通过对不同传感器的综合运用获取这些信息的。
先识别,再处理
如果把车上的感知系统比作人类的触觉和视觉的话,摄像头就相当于车子的“眼睛”。系统从获得道路信息到做出判断可以概括的分为两个阶段:首先是底层信号处理和有用信号的增强,之后再进行图像理解就可以了。为了防止被专业名词搞晕,我们也可以理解为:先把图像看清楚,之后再想想该往哪开。
虽然只有两个步骤,但其中涉及到了许多机器视觉以及人工智能技术的应用。比如“看清楚图像”阶段,要用到图像分割、滤波等等诸多图像处理方面的技术。算法在其中占有非常重要的地位,因为车辆在高速行驶的情况下,需要自动驾驶系统实时的对路面情况作出反应,所以需要算法在能完成本身功能的基础上尽量简洁。

经过图像处理阶段之后,得到了一个计算机可以“看”明白的图像信息,下一步要做的就是“看懂图像”了。在看懂图像阶段就要综合利用模式识别、深度学习等诸多人工智能领域的知识。具体的效果可以用一个识别蛋糕的例子来理解。
比如,给电脑“看”了若干张圆形生日蛋糕的图片,之后再遇到到其它圆形生日蛋糕时,电脑就能识别出这是蛋糕,但如果蛋糕变成方形,电脑就认不出来了。
而让汽车“看懂图片”就是要通过深度学习等方式,让汽车具有更好的识别能力。实现的原理就是给电脑“看”成千上万张各种蛋糕的照片,深度学习系统就会把图像拆分到图层和纹理级别,提炼出它们的共同之处。在使用足够多的图像进行训练之后,电脑的神经网络就可以辨别出各种各样的蛋糕了,无论是它见过的还是没见过的。
不只是摄像头
通过以上步骤的处理,车辆就已经具备通过摄像头获取信息并作出判断的能力了。当然在自动驾驶中,仅仅通过摄像头识别图像是不够的,通常还要搭配毫米波雷达与激光雷达一起使用。激光雷达的监测精度很高,而毫米波雷达在监测障碍物方面会比较有优势。
从成本角度来说,摄像头虽然成本较低,但会受光线等使用环境的影响,而激光雷达的价格又会比较高,像 Google 无人车上使用的 64 线激光雷达成本就要好几万美元。
要实现正真的自动驾驶,就必须综合运用这些雷达和传感器设备,让它们配合使用。很多人觉得自动驾驶在技术方面已经问题不大,但是高昂的成本,仍然是自动驾驶将来普及的一个重要阻碍因素。即使摄像头再聪明,也还得看看其他“同事”的脸色。