

英伟达改写了自动驾驶格局,发布算力2000 Tops的雷神芯片!
雷神Thor来了。
人类有史以来最强自动驾驶芯片,就这样突如其来!
英伟达2022秋季GTC上,黄仁勋发布新一代自动驾驶计算芯片DRIVE Thor。

单颗算力高达史无前例的2000 TOPS,是特斯拉FSD芯片的14倍。
全球大半个自动驾驶圈的芯片,都是黄老爷在贩卖,神通肯定小不了。
但DRIVE Thor问世,还是震惊了所有跟智能汽车相关的人,包括但不限于车圈、科技圈、自动驾驶公司…
因为仅仅半年前,黄仁勋才宣布彼时算力最强的自动驾驶芯片Atlan,1000 TOPS,还说准备量产。
但现在,老黄又改口说Atlan格局小了,干脆取消,直接拿出更加领先一代的量产产品DRIVE Thor。
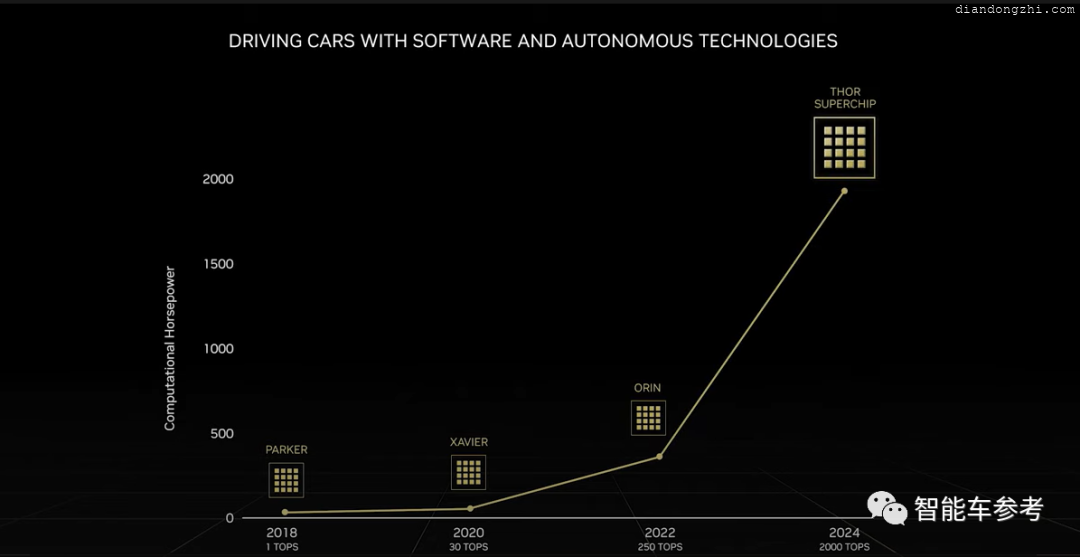
其他芯片厂商还在追赶Orin性能的时候,英伟达的计划是用下一代的下一代,降维打击。
人类史上最强自动驾驶芯片
DRIVE Thor,黄仁勋确认2025年上车量产。
称人类史上最强,首先是参数。
单颗算力2000TOPS,不仅现世量产产品中没见过这么高的参数,即使在一众自动驾驶芯片公司对2025年产品的规划和构想中,也都还停留在数百只至1000 TOPS之间。
所以说,DRIVE Thor是难有争议的代差优势。
而作为替换自家上一代产品Orin,算力数值提升了8倍。
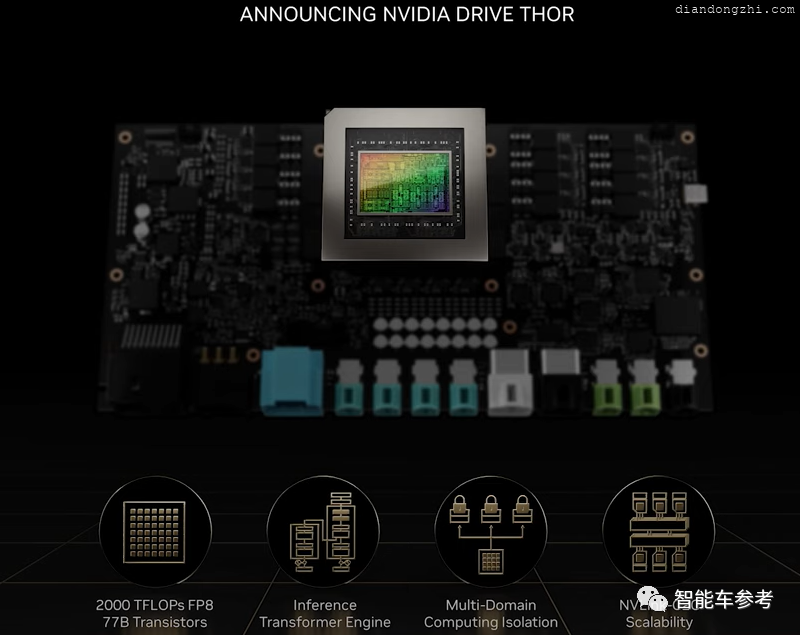
这里还要解释一下算力大小的定义。
一般针对AI任务、自动驾驶的芯片,常用TOPS描述算力,1TOPS代表每秒能进行1012次操作。
所谓“操作”,是指芯片上实现卷积运算的乘加器的基本功能。DRIVE Thor的2000 TOPS意思是每秒进行2*1015次操作。
黄仁勋同时给出了DRIVE Thor性能的另外一个参考维度:2000 TFLOPS。
TFLOPS是描述传统GPU性能的指标,1 TFLOPS指每秒进行1012次浮点运算。

两种单位分属两个不同的描述维度,一般没有绝对的换算关系。但某些特定任务下,1 TFLOPS可以等于1 TOPS。
DRIVE Thor芯片的工艺制程、包含的晶体管数量这些详细信息,英伟达暂未透露。
不过,DRIVE Thor展现出了几个重要的领先性指标,既代表自动驾驶技术未来的发展方向,也是其他同类产品所不具备的。
超高集成度
智能汽车在车辆底层架构方面的最大特征,是从原先数百个ECU控制不同功能,演进到几个集中式域控制器的电子电气架构。
这是目前正在发生的变革。
而几乎所有业内玩家都认为,未来的电子电气架构一定是集中式的,即一个大脑、一个平台或芯片控制汽车所有功能。
架构是车厂的工作,而高度集成化的芯片,英伟达已经做出来了。
DRIVE Thor集成了一辆智能汽车上所需的一切AI功能的计算需求,包括高阶自动驾驶、车载操作系统、智能座舱、自主泊车等等。

车载操作系统中,有对车上所有功能的控制以及不同场景下的联动,也有连接车辆软件层和执行机构的“骨架”。智能座舱方面,则包含仪表盘、娱乐影音、语音识别交互等等。
2000TOPS的算力资源,主机厂可以在各种不同AI任务间随意分配,英伟达提供相关开发工具。
一颗芯片解决所有,DRIVE Thor可能不便宜,但肯定比采购一堆芯片划算。
One chip to rule them all!
支持超大规模AI模型运算
DRIVE Thor为这两年自动驾驶流行的超大规模Transformer准备了专用引擎。
最初的Transformer来自于NLP(自然语言处理)领域。从输入层开始,Transformer每一层结构都可以看到所有的信息,并且建立基本单元之间的关联。
因此Transformer天然具备超强序列建模能力、全局信息感知能力的特点。
应用到自动驾驶中,Transformer主要干两件事,对于投影像素平面的“刻画”、以及对于投影平面和BEV平面之间的“转化”。

特斯拉最早将Transformer用在自动驾驶任务中,而如今几乎所有玩家都跟进。
Transformer网络的参数规模,从一开始的百万级数,到十亿级,再到现在的万亿级,一直呈指数级增加。
DRIVE Thor上的Transformer引擎,能够将视频数据作为一个单一的感知帧来处理,使计算平台能够在固定时间内处理更多的数据。
集英伟达技术大成
黄仁勋特别解释了DRIVE Thor超强性能的根源:
Grace、Hopper、Ada Lovelace。
Grace是英伟达的AI专用服务器CPU,基于ARM架构,也是英伟达进军CPU领域的第一款产品,Grace高度专业化,走的是和GPU向结合的道路,适用于AI 和高性能计算工作。
使用第四代NVIDIA NVLink互联技术与GPU相融合后,可以处理超过1万亿参数的AI模型训练任务。
Hopper是英伟达最新的GPU架构之一,其实也是英伟达押注AI的一场豪赌:
将传统 GPU 计算引擎集中在神经网络转换器模型上,并将DGX系统扩展为能够在机器学习训练中支持数万亿个参数。
Ada Lovelace么,当然就是刚发布的40系列显卡新架构。4nm制程,流式多处理器具有高达83TFLOPS 的着色器能力,吞吐量超过上一代产品2倍。

老黄的意思很明白,DRIVE Thor在深度神经网络任务上,采用Grace+Hopper的CPU、GPU混合架构。
而在具体的图像处理任务,则和最新的40系列显卡相同。
是不是说明,DRIVE Thor也采用台积电4nm工艺?
其实从2025年量产节点看,DRIVE Thor采用2-3年前的消费级芯片成熟架构和工艺,完全符合车规芯片对可靠性的要求和行业惯例。
从摩尔定律来看,芯片集成度的突破已经逼近极限,4nm制程的车规AI芯片量产时,也许和手机、电脑上的消费级处理器差距很小了。
这可能也是DRIVE Thor带来的另一个里程碑:车规芯片不再有代差。
英伟达的智能车税,只靠算力吗?
当然不是,另一个竞争力,是英伟达开放的平台特性和全套完整的开发工具。
不过,老黄今天介绍的,都是基于已经量产的Orin芯片相关平台展开。

NVIDIA DRIVE,是一整个自动驾驶开发平台,既包括硬件Orin芯片,也包含英伟达提供的模拟测试搭建工具、地图环境实时构建、安全相关测试,以及一些基础的已经训练好的算法模块参考。
在一个自动驾驶算法典型的开发过程中,路测车辆行驶时,NVIDIA DRIVE能够直接从环境信息中心采集各类不同物体的信息,并完成建模分类,然后储存在数据库中,以便日后模拟训练时使用。

这些数据可以做到非常细致,比如带有长宽高以及深度信息的4D图像数据:

根据自动驾驶方案选择的传感器不同,NVIDIA DRIVE也可以针对不同传感器分别建立储存数据信息。
同时,系统还会实时记录绘制地图路线信息,保存在数据库中。
对真实环境信息实时采集,并保存素材的目的是什么?
当然是为高效的模拟测试开发做准备。模拟取代实际路测,这也是如今自动驾驶开发的一个热门趋势。
总之,英伟达不但给自动驾驶算力最大的芯片,如果你想,还会给你高度自动化,甚至是“傻瓜式”的开发工具。
算力一步登天的首发车企,竟是他?
2025年量产2000TOPS的DRIVE Thor,谁第一个实现“算力自由”?
极氪汽车。
你没看错,国产自主一哥吉利旗下的纯电品牌——
那个一直以机械素质见长,提起智能化却人人摇头的极氪汽车。

能不能赶上首发上市,要看车型研发进度。但明确签约要上车DRIVE Thor的,极氪的确是第一个。
搭载DRIVE Tho的会是什么样的车?
从业内普遍认知行和已经展现出的规律来看,一般L2级辅助驾驶,需求的算力在几十TOPS左右。
智能驾驶每提升一个级别,需求算力也呈指数上涨。
例如,目前行业普遍站在L2迈向L3的门槛,需求的算力在几百TOPS左右。
而为未来几年算法迭代发展留足升级空间的产品,一般都把算力堆到1000TOPS以上,也就是4块Orin芯片的方案。

显然,他们设置的最远规划,是L3人机共驾向高阶智能驾驶过渡阶段。
这个时间点,在DRIVE Thor出现之前,大家的共识是2025年。
也就是说,自动驾驶研发的节奏,是按照2025年L3迈向L4,车端算力刚好在1000T左右的预想规划。
DRIVE Thor如果顺利于2025年上车,造成的影响一定是深远的。
最重要的,是客观加速自动驾驶能力的迭代周期。毕竟,这是史上第一次出现“算力等算法”的情况。
其次,DRIVE Thor上车,更加彻底的改变汽车底层架构,在智能化的核心价值上走得更远更极致。

当然也会加速传统汽车淘汰出局。
最后总结一下,老黄和英伟达今晚展示的产品和趋势,一定会写入自动驾驶大事记,成一个里程碑式转折。
那么接下来,还有不到10天就是特斯拉AI DAY,会不会出现更加意料之外、震撼人心的产品或技术?
压力现在来到马斯克这边。
最后By the way,英伟达最新4的0系列显卡,7199元起,最高的RTX 4090售价12999元,冲吗?
出处:见配图水印